
Thoughts on Platforms, Core Teams, DORA Report and all that jazz

All the best in New Year!
Here’s my summary of 2024: I survived! And that’s a success that I want to repeat in 2025.
Right before Christmas, I wrote a longer thread on social media with my thoughts on the hot topic: platform teams. I see many of my clients trying to apply it, some succeeding, some more, but all struggling. I’m not an expert in the internal platforms, but I was a part of the core teams, shaping continuous integration and delivery processes, and I see many similarities.
As my thoughts spin up some good discussion (see here or there), I decided to share it with you today. And that’s a free post, so if you enjoyed it, feel free (pun intended) to share it with your friends!
The challenge
The longer we work on some code, the more polished it gets? Actually, it’s not always like that. Past me believed in shared reusable code. Now, I’m looking at it from a different angle. Platforms, shared code, core libraries are many faces of the same issue. We try to build one tool to rule them all, which never works. At least for a longer time.
We try to centralise the code and by that common understanding. Yet, we usually end up with a common misunderstanding.
Whether you call it a “platform team“ or a “core team” the nature of the struggle remains the same: both groups aim to provide foundational solutions across the organization. They often wrestle with the same problem—trying to anticipate every scenario in a single, central codebase or service. Over time, these monolithic solutions become harder to maintain, and the team maintaining them drifts away from the real-world issues developers face day-to-day. That’s how both platform and core teams can fall into the trap of delivering an all-in-one system that erodes under the weight of endless patches and shifting priorities.
The fallacy of the one to rule them all
I believe that even in internal projects, we should focus more on small, focused tools rather than a monolithic platform. Tools are built for something; they don’t need to fulfil every possible scenario but can instead focus on a specific area. And I don’t mean only technical tools; I’m also talking about business features for user-facing areas—think back offices.
Why does that matter? For most of our business, building one massive internal solution won’t ever be a business per se. It can only be a priority when it truly provides direct business value.
That’s how we get to the counterintuitive part of “the longer honed, the better.” Those big core/platform components tend to be the most stable after one or two years when we already have a solid grasp of what we’re doing. Then, they slowly degrade as the need for rapid delivery of internal capabilities becomes a priority, and teams focus back on their domain.
Don’t believe me? Check this diagram from DORA Accelerate State of DevOps report 2024:
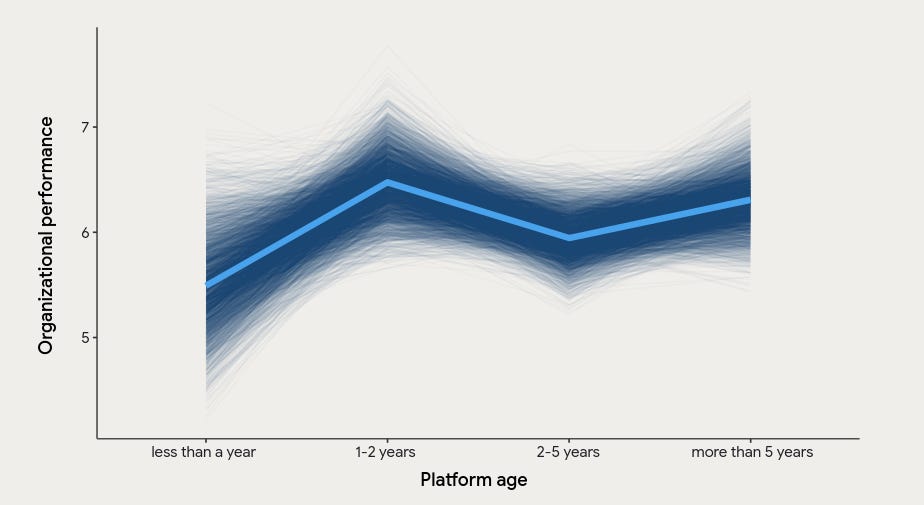
Do you see the peak in 1-2 years? That’s when erosion starts.
When we add more features, we already get an understanding of what we do. Then, they slowly degrade as the need for rapid delivery of internal capabilities slows down and thus becomes a priority. Teams start to focus on their domain.
Adding a quick patch to a stable core won’t seem like a big deal, but it piles up. Meanwhile, the tech landscape is changing. Better tooling emerges, and our homebrew solutions become obsolete. Add to that the fact that it’s hard to justify constantly working on a tech-focused platform that, according to management, “should have been already done.”
Then, the platform team often becomes detached from the daily struggles of other teams, and we start seeing Conway’s Law in action. Not great. What does that mean, detached?
they lose connection with what business features are delivered,
they see just the narrowed internal view of the delivery process, losing the overall scope,
they start to be seen as cost-only teams, as they have a hard time showing the exact impact of their internal, technical solutions for the benefit of the other teams.
If you think that’s only my anecdotal evidence, check the interesting findings from the DORA report.
It can bring the instability of the development process:
In the case of throughput, we saw approximately an 8% decrease when compared to those who don’t use a platform. We have hypotheses about what might be the underlying cause. (…)
In general, when an internal developer platform is being used to build and deliver software, there is usually an increase in the number of “handoffs” between systems and implicitly teams. (…)
Each of these handoffs is an opportunity for time to be introduced into the overall process resulting in a decrease in throughput, but a net increase in ability to get work done.
And on skewed perspective of the organisation about the platform team impact:
Interestingly, the impact on productivity of having a dedicated platform team was negligible for individuals. However, it resulted in a 6% gain in productivity at the team level. This finding is surprising because of its uneven impact, suggesting that having a dedicated platform team is useful to individuals, but the dedicated platform team is more impactful for teams overall.
Generic does not mean Simple
That’s why I always say, “Generic does not mean Simple”. Reusability and maintainability are not values per se.
My suggestion is to focus on delivering precise business or tech tools. You may not need to maintain them forever, and it can be simpler to justify and explain to management why you must keep them fresh. Of course, it’s less sexy than playing with the newest stack, but it pays off in the longer term.
That’s what I was also doing with my OSS work. I have Event Sourcing samples that I delivered in the form: “Take them in whole or parts, adjust to your needs.” Then, observing how people interacted with them and seeing the usage patterns motivated me to pack them into the reusable toolbox like Emmett.
You can do it in the same way in your regular projects. Of course, we need to be careful. Copy/pasted templates can help, but they’re also cumbersome if we need to update them later and replicate organisational changes.
It’s more about “catalogue how we do it” than “enforce how we must do it”, aiming to reduce the boring, repeatable setup.
Creating a generic internal platform from the very beginning of a project can introduce artificial limitations. We’re making those hard decisions at the worst possible moment: when we’re dumbest. We don’t know the tech stack or the domain; we’re shaping our product vision. We try to predict where and how the business and tech will evolve. Frankly, we’re more guessing than predicting.
It’s often a sign of being too self-assured or short-sighted: it’s easy to whip up the solution that feels quick and friendly for a single case, but once we reach the long tail of features, we realize we didn’t anticipate everything.
For example, rather than providing an all-encompassing core “everything module” that does automatic mapping, calls pluggable services, generates docs automatically, and so on, it’s more sustainable to offer smaller modules specifically focused on handling particular concerns. A huge internal platform must handle all possible scenarios, and maintainers must guess the usage. In contrast, smaller, dedicated solutions let teams solve specific use cases based on the patterns they want to promote.
People can also diverge more easily and adopt new tech when they’re not locked into an all-encompassing internal platform. It’s simpler to remove a small, now-obsolete piece of code than to tear out something massive. Plus, when multiple teams use those small modules, they can contribute improvements and provide feedback.
Let’s quote the DORA report again:
A key factor in the success is to approach platform engineering with user-centeredness (users in the context of an internal developer platform are developers), developer independence, and a product mindset. This isn’t too surprising given that user centricity was identified as a key factor in improved organizational performance this year and in previous years. Without a user-centered approach, the platform will be more a hindrance rather than an aid. (…) Recall that in thecontext of the platform, users are internal engineering and development teams. (…)
First, prioritize platform functionality that enables developer independence and self-service capabilities. When doing this, pay attention to the balance between exclusively requiring the platform to be used for all aspects of the application lifecycle, which could hinder developer independence.
Plaform takes the pain
I love the term Platform Takes The Pain; it’s a great motto stated by Pia Nilsson, responsible for the Spotify platform. She explained it in the Corecursive Podcast episode. She told how they transitioned from isolated teams into a centralised but focused platform. It’s a great story about transitioning the platform team mentality from playing with CI/CD tools and experimenting to becoming an enabling team for others.
So yes, centralisation is not always bad. Some elements—like cross-service communication, documentation, or security—have to be enforced to maintain consistency, but for most things, gentle guidance is enough.
Spotify realised that the platform should not be the elitist team enforcing others' behaviour but helping them proactively, contributing hand in hand to introducing the new approach. That means making the actual Pull Requests to business modules modernising their way.
That’s also a similar piece of advice that Hazel Weakly did in our webinar on Applying Observability. She told how to add observability and instrumentation:
But the teams will never have time to do this. If you ask them to do it, it'll take months, it'll take quarters. So you have to just say, we're going to grab a couple people full-time, run through, and have those people do absolutely one thing.
The manual instrumentation and the setup just over and over and over and over. They're going to get sick of it, and they're going to get tired of it, but they're going to get really efficient at it. And they're going to do some rip through the code base, make a whole bunch of pull requests, and do that.
When that happens, when that's through, when that's done, you are good to go. (…) Once you set up that skeleton and developers can low effort, see the code and copy paste it and do their own thing, you are good to go. You are, it won't start happening. You've lowered the barrier of entry. And that is the magic of observability is lowering the barrier of entry.
If it's too high, people are never going to want to sit down and understand it. They need to almost accidentally be able to learn it rather than have to dedicate time on the weight.
Such an approach helps to set the priorities right, so enabling, not enforcing.
I saw that platform teams believe they’re the foundational and elitist team. At the same time, they’re there to help others deliver business value. We need to avoid the story shared by Ben Dumke-von der Ehe on his work in the Stack Overflow core team.
It was the core Stack Overflow team, and I was on that team. And one day, our manager came into chat and said, “We’re thinking about renaming the core team to Q&A team, because it has this favoritism thing that it kind of implies, in a way.” And I went… I don’t want to say I went apeshit, not that bad, but I was all up in arms and saying something like, “Are you accusing us elitism? Because we are not elitist. And we respect everybody, yada, yada.”
And couple years later, when I then read that back, I so wanted to smack my past self over the head, because it made zero sense.
It wasn’t about us. It wasn’t about us that were being perceived as elitist or not. It was about the fact that everybody else was feeling second class, because, “That’s the core team, and we’re just the rest.” That was about them and not us.
I have observed in the past that there's a weird scenario. Platforms/core teams are often formed with the best technical people. In theory, they should form the best team, but in practice, it's not like that.
This is a dangerous mixture, as people in the core team are aware of those criteria and get (sub)consciously the elitism feeling. That creates tension between teams as, in theory, they're the best but also highly paid and have a hard time showing the business benefits of their actions.
The regular teams can see them as "why they're considered best if we're bringing income, and they're only bringing costs." As I mentioned in the article, the DORA report also shows that.
That's also why I like the phrase "Platform takes the pain", as it highlights that it should be a business-enabling team.
Pitfalls and solutions
Part of the problem is also a mix of lack of trust and the mistaken assumption that centralizing everything will save development time overall. Early on, it might—but soon, the Pareto principle hits, and we spend 80% of our time on the last tricky 20%. I’ve fallen into this trap myself, creating classes with 14 generic parameters or pipelines that claimed “zero config.”
This quickly becomes a vicious circle: by dictating everything from the centre, we don’t teach genuine ownership or a learning path.
I’ve witnessed plenty of trouble arising from piling everything into one core. It might not be obvious initially, but after a year or two, a single, centralized repository of random code becomes an unmaintainable anchor. That’s not to say it can’t work—it’s just more likely to work with smaller teams that share an understanding of the domain. It’s also about how much knowledge each team has and how we foster continuous learning.
A helpful tool might say: “If you stick to the recommended approach, you get OpenAPI for free. If you don’t, that’s fine, but then you own it and must maintain it.”
Or another example: When building CI/CD pipelines, avoid magical, behind-the-scenes processes. Instead, provide plugins or templates with safe defaults. Infrastructure-as-Code tools like AWS CDK enable building well-defined components rather than black boxes.
In this way, we’re showing people benefits. We’re giving them a carrot, not only a stick, and the option to diverge if that makes sense. It also gives people ownership and makes them accountable.
As Charity Mayors say, you build it, you run it.
She gave a nice talk on Perils, Pitfalls and Pratfalls of Platform Engineering. She outlined the following pitfalls in her talk:
Running Too Much Software.
Writing Too Much Software.
Not Letting Product Teams Own Their Own Reliability.
Not Giving Engineers Enough Tooling to Understand Their Code as Well as Operate It
Being Confused About Who Your Customer Is.
Not Running Your Team Like a Product Team.
Not Paying Enough Attention to Cost and Spend as Part of Architecture and Planning
Not Constantly Looking for Ways to Deprecate, Delete, and Shed Responsibilities.
And that nicely wraps up what we should avoid and what we have also discussed so far.
Platform as a back-office
I love the idea that Andreas Pinhammer explained in his talk: DDD in large product portfolios.
A key takeaway was how their “platform team” became a business back-office focused on enabling others instead of just a “Kubernetes-and-other-technical-stuff” team.
They focused on business features that are not user-facing but can help other business teams do things faster. A good example of that could be payment module-as-a-platform. Multiple modules can require payments, so there’s no point in repeating those features all around.
We can gather the requirements and form a dedicated team responsible for delivering business capabilities to other teams.
There are good tools that can help in that, like Context Mapping and Team Topologies. You can start with those two talks:
Introduction to Context Mapping by Michael Plöd
Monoliths vs Microservices is Missing the Point—Start with Team Cognitive Load - Team Topologies by Matthew Skelton and Manuel Pais,
Autonomy, is that what we really want? by Kenny Baas-Schwegler
Systems Thinking by combining Team Topologies with Context Maps by Michael Plöd
Architecture for Flow - Wardley Mapping, DDD, and Team Topologies by Susanne Kaiser
In short, that’s also the impact of the Conway Law that we just cannot avoid. We discussed that in detail in:

Final advice
If you’re already in the scenario where your platform/core is going rogue, I suggest focusing on delivering exact business instead of tech tools. You can start with the following steps:
Identify the “big internal platforms” or “core systems” that have grown beyond their original intent. Then, start breaking them down into smaller, specialized capabilities and tools.
Prioritise business capabilities over purely technical solutions. No, Kubernetes is not a platform; it’s a technical tool that can help with this.
Enforce only critical aspects (security, docs, cross-module communication) while letting teams shape the rest to their needs.
Encourage solutions that teach, offering safe defaults for most people while giving advanced users room to experiment.
Involve multiple teams in maintaining these smaller tools so everyone owns the improvements and shares what they have learned.
By that, we adapt by delivering smaller, targeted solutions, better tooling, and real synergy between operations, coding, and design. It’s all about enabling teams to be effective, accountable, and ready to adjust as our business grows and our tech evolves.
Of course, it’s less sexy than playing with the new tech stack, but it will pay off in the longer term.
What are your experiences, challenges, and pieces of advice? Please share them with me; I’m more than curious!
Cheers!
Oskar
p.s. Ukraine is still under brutal Russian invasion. A lot of Ukrainian people are hurt, without shelter and need help. You can help in various ways, for instance, directly helping refugees, spreading awareness, and putting pressure on your local government or companies. You can also support Ukraine by donating, e.g. to the Ukraine humanitarian organisation, Ambulances for Ukraine or Red Cross.